

作为一名Web开发者,JavaScript是我们必修的技能,在这个类库满天飞的时代,使用类库让我们的开发效率调高了很多倍,但是同时也带来了一些弊端,越来越多的开发者开始对类库产生依赖,从来不思考底层是如何实现的,一旦脱离了类库,那么就什么都不会了,所以我想说的是,要想在Web开发这条路上越走越远,还得返璞归真,了解原生的东西,那么本篇文章的重点就是教大家如何使用原生JS实现各种JQuery的操作。
框架能够让我们走的更快 , 但只有了解原生的语言才能让我们走的更远 – 鲁迅

Node、NodeList 与 HTMLCollection
人们称赞JQuery大多是因为它极大地简化了操作DOM的方式,获取一个元素仅仅通过一个简单的$符号后面跟上选择器即可,那么脱离JQ,使用原生JS操作DOM,就不得不提这3个东西了:
Node
顾名思义,Node就是节点的意思,它是一个接口,很多DOM元素都继承于它,所以它们都拥有Node的属性与方法,常见的DOM有element(元素),text(文本),attribute(属性),comment(注释),document(文档)等等。
NodeType
Node类型拥有NodeType属性,它是一个整数,以下是它表示的相应的Node类型:
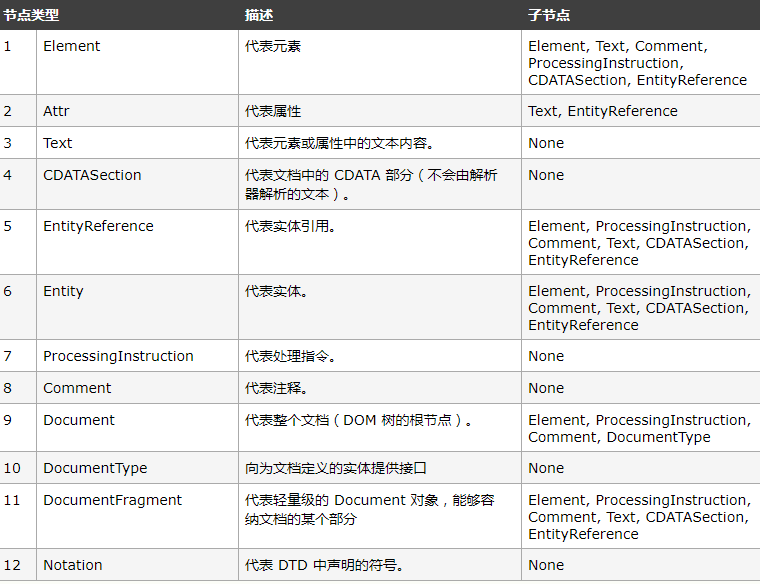
NodeName 与 NodeValue
Node类型还拥有2个属性NodeName,NodeValue,以下是不同的Node类型调用这2个属性时的相应返回值:
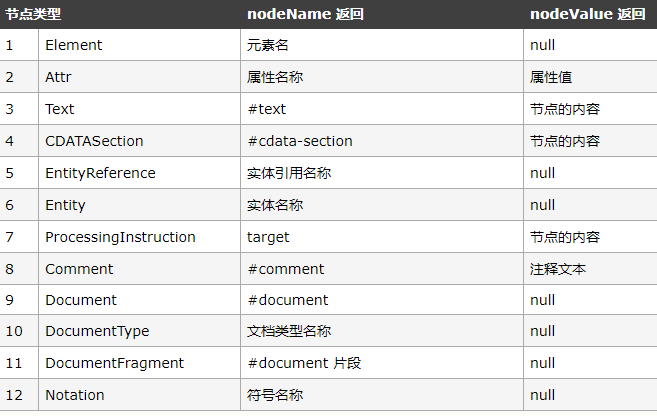
NodeList
NodeList对象是一个节点的集合,是由Node.childNodes 或 document.querySelectorAll 或 getElementsByName返回的。
NodeList对象拥有length属性,它返回NodeList对象中包含节点的个数。
NodeList对象拥有item(index)方法,它返回NodeList对象中指定索引的节点,若不存在则返回null,等价的写法是nodeList[index], 不过这种情况下越界访问将返回undefined.

大多数情况下,NodeList是一个实时集合。意思就是说,如果文档中的节点数发生变化,则已存在的NodeList对象也会变化。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<script>
var child_nodes = document.body.childNodes;
console.log(child_nodes); //output: NodeList(2) [text, script]
document.body.appendChild(document.createElement('div'));
console.log(child_nodes); //output: NodeList(3) [text, script, div]
</script>
</body>
</html>
由上面这个例子可以看出NodeList对象确实是实时更新的,所以当你在遍历NodeList对象进行删除元素时,要牢记这一点
不过需要注意的是,通过queryselectorAll返回的虽然确实是NodeList,但是它底层实现类似于一组元素的快照,并非是不断地对文档进行搜索进行动态查询,也就是并不是实时更新的,这一点有好处也有坏处,好处是可以避免由NodeList引起的大多数性能问题,坏处就是不能操作未来元素。
使NodeList拥有数组方法
NodeList是一个类数组对象,但它不是一个真正的数组,所以它无法直接继承Array.prototype上的方法,当然,解决办法也很简单:
//方法1 call
var divList = document.querySelectorAll('div'); //返回 NodeList
var divArray = Array.prototype.slice.call(divList); //将 NodeList 转换为数组
//方法2 ES6语法 Array.from();
var divArrayFrom = Array.from(divList); //将 NodeList 转换为数组
HTMLCollection
HTMLCollection 同样是一个接口,与NodeList对象很相似,它表示 HTML 元素的集合,它提供了可以遍历列表的方法和属性。
通过document.getElementsByTagName 或 getElementsByClassName 或 document.forms 获取的都是HTMLCollection对象
HTMLCollection 对象拥有length属性,这个属性返回当前集合中子元素的数目。
HTMLCollection 对象拥有item(index)方法,这个方法根据给定的索引(从0开始),返回具体的节点,若不存在,则返回null。
HTMLCollection 对象拥有namedItem(string)方法,这个方法根据给定的ID返回具体节点,若不存在ID则作为name进行匹配,所匹配的节点必须拥有name属性。
<form id="myForm"></form>
<form name="myForms"></form>
<script>
var foo, bar;
foo = document.forms[0];
bar = document.forms.item(0);
console.log(foo === bar); //output: true;
foo = document.forms["myForm"];
bar = document.forms.namedItem("myForm");
console.log(foo === bar); //output: true;
console.log(document.forms["myForms"]); //output: <form name="myForms"></form>
</script>
选择器
JQuery的选择器使用了Sizzle引擎,所以性能是很高。但是再高也没有原生高,并且在大多数情况下,我们完全可以使用差不多的代码量完成一样的工作,性能还比JQuery高出很多,何乐而不为呢?
//根据ID查找 返回元素 若有多个相同ID的元素 只返回第一个
document.getElementById('myId');
//根据标签名查找 返回HTMLCollection对象
document.getElementsByTagName('div');
//根据类名查找 多个类名使用空格分开 返回HTMLCollection对象
document.getElementsByClassName('myClass');
//根据name属性查找 返回NodeList对象
document.getElementsByName('myName');
//根据css选择器查找集合中的第一个元素
document.querySelector('.myClass');
//根据css选择器查找 复杂一点的选择器也是可以的 返回静态的NodeList对象
document.querySelectorAll('.myClass li:first-child');
如果页面中会多次用到一个选择器,那么我们可以将他封装到函数里,就像JQ的$一样,例如:
/**
*
* @param c CSS选择符
* @param a [可选] 默认返回第一个元素 传入true则返回元素集合
* @returns {Element || nodeList}
*/
function L(c,a){ return a ? document.querySelectorAll(c) : document.querySelector(c) }
/**
*
* @param c CSS类名
* @param a [可选] 默认返回HTMLCollection 传入true则返回第一个元素
* @param f [可选] 祖先元素 传入祖先元素 则根据祖先元素下查找
* @returns {HTMLCollection || Element}
*/
function C(c, a, f){
if(a){
return f ? f.getElementsByClassName(c) : document.getElementsByClassName(c);
}else{
return f ? f.getElementsByClassName(c)[0] : document.getElementsByClassName(c)[0];
}
}
经测试,getElements方式与querySectorAll比较,前者速度更快,但后者是静态的nodeList,所以具体场景具体选择。


